Getting Started with Sangria
Sangria is a Scala GraphQL implementation.
Here is how you can add it to your SBT project:
libraryDependencies += "org.sangria-graphql" %% "sangria" % "4.0.0"
You can find an example application that uses akka-http with sangria here:
https://github.com/sangria-graphql/sangria-akka-http-example
I would also recommend you to check out https://github.com/sangria-graphql/sangria-playground. It is an example of a GraphQL server written with the Play framework and Sangria. It also serves as a playground, where you can interactively execute GraphQL queries and play with some examples.
Apollo Client is a full featured, simple to use GraphQL client with convenient integrations for popular view layers. Apollo Client is an easy way to get started with Sangria as they’re 100% compatible.
If you want to use sangria with the react-relay framework, then you also need to include sangria-relay:
libraryDependencies += "org.sangria-graphql" %% "sangria-relay" % "2.0.0"
Sangria-relay Playground (https://github.com/sangria-graphql/sangria-relay-playground) is a nice place to start if you would like to see it in action.
Before you start, you might want to check out “Videos” section of the community page. It has a lot of nice introduction videos.
GraphQL Introduction
GraphQL is a data query language. It was developed by Facebook and in July 2015 a first draft of the specification was released publicly. Here is an example of GraphQL client-server interaction:

As you can see, it’s a typical HTTP-based client server interaction, where the client makes a POST HTTP request with GraphQL query in a post body and the server returns a JSON response. Though HTTP transport and JSON data format are not part of GraphQL specification and are not prescribed by it, it’s the most popular option for GraphQL server, so next sections will use these for examples.
Conceptually, during this interaction, both client and server provide important pieces of information to each other:

Since GraphQL has a type system, the server defines a schema which the client can query using the introspection API. This provides the client with a set of possibilities. After the client got this information and decided which parts of the data it needs, it is able to describe its data requirements in form of GraphQL query.
Important aspect of GraphQL is that it’s completely backend agnostic. This means that you are free to choose the transport protocol, exposed data format, the data storage engine, etc. GraphQL and Sangria are just a thin layer inside of your Scala application that controls the execution of your business logic:

In the next sections we will go through the steps that will help you to build your own GraphQL server with Scala and Sangria:
- Define a GraphQL schema
- Test the schema
- Expose a GraphQL endpoint via HTTP (with akka-http and play)
If you would like to learn more about GraphQL itself, I would highly recommend you to visit the official GraphQL website.
Define a GraphQL Schema
Just like Scala, GraphQL has a powerful type system behind it. This means that we need to define the meta-information about the schema in
our Scala code with abstractions provided in sangria.schema package.
Here is an example schema that we will implement (described with GraphQL syntax):
type Picture {
width: Int!
height: Int!
url: String
}
interface Identifiable {
id: String!
}
type Product implements Identifiable {
id: String!
name: String!
description: String
picture(size: Int!): Picture
}
type Query {
product(id: Int!): Product
products: [Product]
}
As you can see, you can define types and interfaces in GraphQL, just like in Scala. Exclamation mark (!) means that field is mandatory and
cannot return null values. Square brackets ([...]) signify the list types. GraphQL type system has enums, union types, scalars
and input object types, but we will not go deeper into these in this particular example.
Here is an example of GraphQL query that we will be able to execute against this schema:
query MyProduct {
product(id: "2") {
name
description
picture(size: 500) {
width, height, url
}
}
products {
name
}
}
Note that we start the query with product and products fields. These fields are defined on a Query type and serve as a main entry point.
We will discuss it in more detail later.
Picture Type
First let’s define a Picture GraphQL type. In scala, you most probably will model it a simple case class like this one:
case class Picture(width: Int, height: Int, url: Option[String])
Let’s define a GraphQL object type for it:
import sangria.schema._
val PictureType = ObjectType(
"Picture",
"The product picture",
fields[Unit, Picture](
Field("width", IntType, resolve = _.value.width),
Field("height", IntType, resolve = _.value.height),
Field("url", OptionType(StringType),
description = Some("Picture CDN URL"),
resolve = _.value.url)))
This is the most common way to define the GraphQL schema with Sangria. An ObjectType allows you to specify name, description
and a list of fields that describes the Picture type. We also have defined this GraphQL type in terms of our, previously defined, Picture
case class. In order to identify what every GraphQL field should return during the query execution, we have provided a resolve function for
every field. resolve function plays quite an important role since this is the place where you can define your own business logic.
In this simple example we just use the context value (which would be of type Picture) and extract specific property value from it.
But we can also perform more complex logic in this function, even access the data storage as we will see in the later example.
You probably noticed that it requires a lot of extra code to define a GraphQL type, especially considering that we already have the Picture case class
which already contains a lot of information about our domain object. For situations like this, Sangria provides a set of macros that help you
to derive GraphQL definitions based in Scala classes.
Let’s simplify the GraphQL object type definition for Picture with deriveObjectType macro:
import sangria.macros.derive._
implicit val PictureType =
deriveObjectType[Unit, Picture](
ObjectTypeDescription("The product picture"),
DocumentField("url", "Picture CDN URL"))
Macro allows you not only to derive the structure of the case class and appropriate resolve functions for all of the derived fields,
but it also allows you to customize different aspects of the generated GraphQL object through macro arguments. In this case we added
additional documentation to the object type itself and one of its fields, but you can also customize any aspect of generated GraphQL object this way.
Product Type and Identifiable Interface
Next let’s define an interface for all types that have an id field. Scala equivalent will look like this simple trait:
trait Identifiable {
def id: String
}
The GraphQL definition will look pretty similar to what we saw before, but we will use an InterfaceType instead:
val IdentifiableType = InterfaceType(
"Identifiable",
"Entity that can be identified",
fields[Unit, Identifiable](
Field("id", StringType, resolve = _.value.id)))
Now that we have an Identifiable interface, let’s define a Product scala case class and equivalent GraphQL definition with
deriveObjectType macro:
case class Product(id: String, name: String, description: String) extends Identifiable {
def picture(size: Int): Picture =
Picture(width = size, height = size, url = Some(s"//cdn.com/$size/$id.jpg"))
}
val ProductType =
deriveObjectType[Unit, Product](
Interfaces(IdentifiableType),
IncludeMethods("picture"))
By default, macro will only consider the case class fields. In this example we explicitly asked macro to include picture method.
We also defined an implemented interface since this does not happen by default. deriveObjectType macro is also able to handle method
arguments and translate them to GraphQL field arguments.
Query Type
Finally we need to define a Query type. Query type is a bit special because it will define the top-level fields. You will use these
fields as an entry point in your GraphQL queries. Otherwise Query is the same object type that we already defined several times earlier.
This time around, let’s define it as a normal ObjectType, but before we will do this, we need to define a product repository
which will be responsible for loading the product information from a database or external service. For a simplicity sake, let’s just use an in-memory
product list in this example:
class ProductRepo {
private val Products = List(
Product("1", "Cheesecake", "Tasty"),
Product("2", "Health Potion", "+50 HP"))
def product(id: String): Option[Product] =
Products find (_.id == id)
def products: List[Product] = Products
}
Now let’s define a Query type:
val Id = Argument("id", StringType)
val QueryType = ObjectType("Query", fields[ProductRepo, Unit](
Field("product", OptionType(ProductType),
description = Some("Returns a product with specific `id`."),
arguments = Id :: Nil,
resolve = c => c.ctx.product(c arg Id)),
Field("products", ListType(ProductType),
description = Some("Returns a list of all available products."),
resolve = _.ctx.products)))
As you may noticed, we have defined Query type in terms of ProductRepo, but we have provided it as a first type argument this time around.
We do not have a context value in this case because this type is an entry point for the whole query. Sangria allows you to provide user
context object which is available to all GraphQL type fields within the schema. The type of this object is provided via the first type argument.
In most cases this user context object provides access to a data storage (like database or external service), auth information and generally information that is common
and may be useful to all of the fields in your GraphQL schema.
Now that we have defined the Query type, the only thing we need to do is to define the schema itself:
val schema = Schema(QueryType)
Schema Execution
Given this schema definition, we now can execute queries against it. Let’s write a small test and execute an example query against our schema.
For testing purpose, Sangria provides very convenient graphql macro which parses a GraphQL query and reports all syntax errors as a
compile-time errors, if there are any:
import sangria.macros._
val query =
graphql"""
query MyProduct {
product(id: "2") {
name
description
picture(size: 500) {
width, height, url
}
}
products {
name
}
}
"""
For a query execution we will use Executor.execute method which will also require a user context object (ProductRepo in our case):
import sangria.execution._
import sangria.marshalling.circe._
import io.circe.Json
val result: Future[Json] =
Executor.execute(schema, query, new ProductRepo)
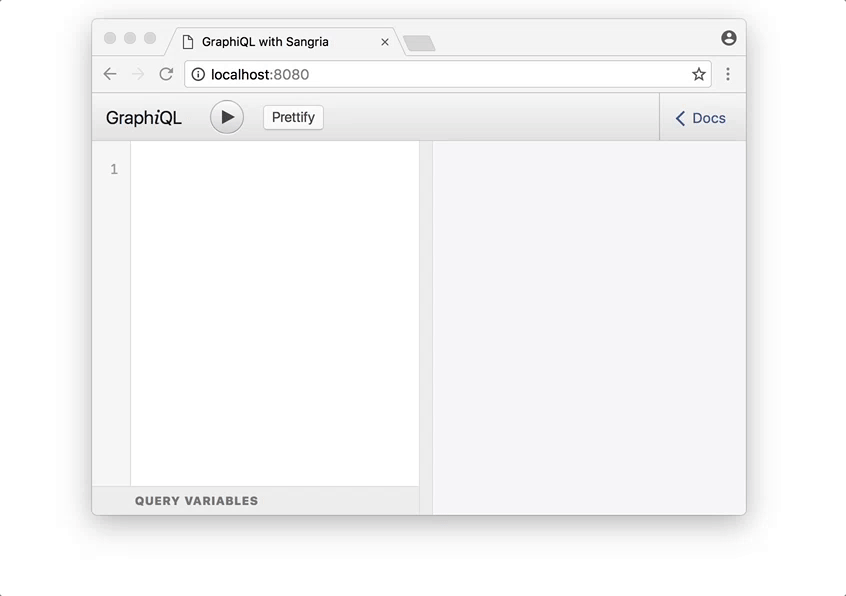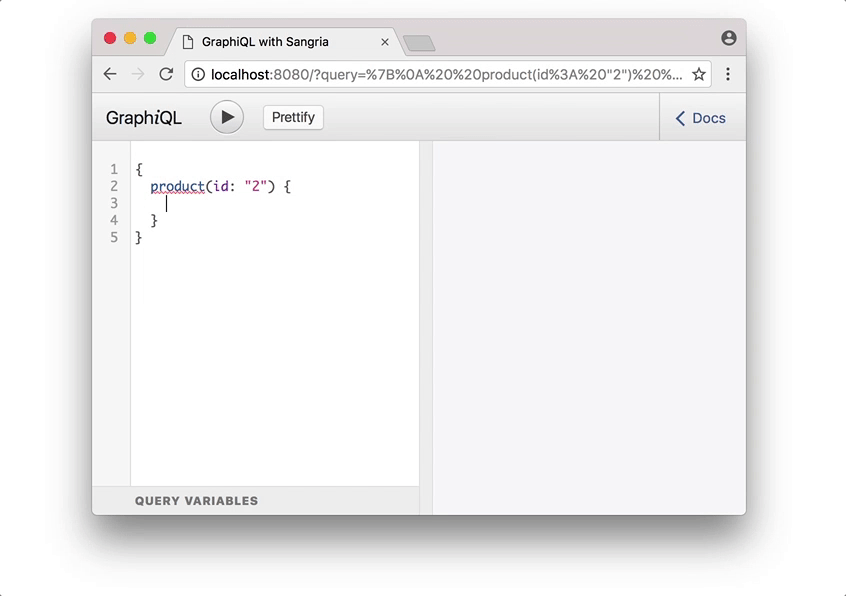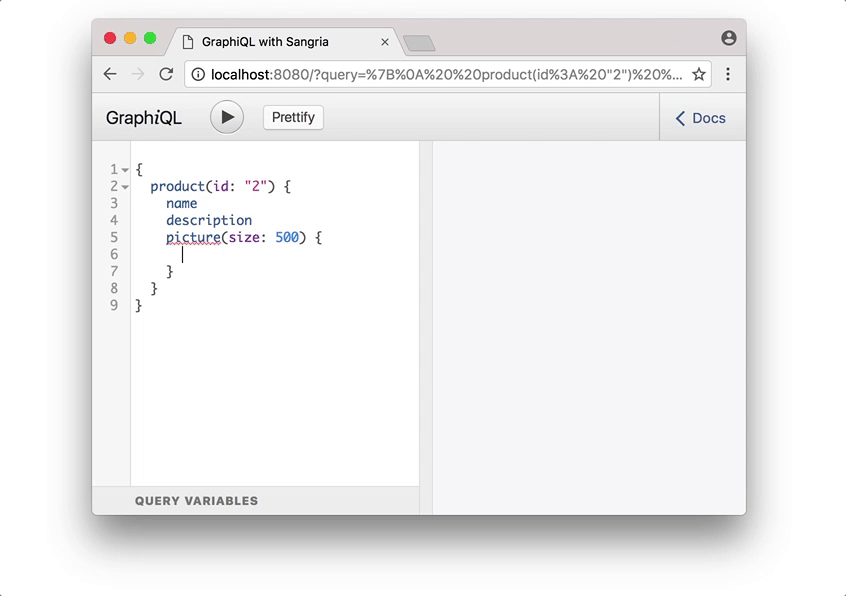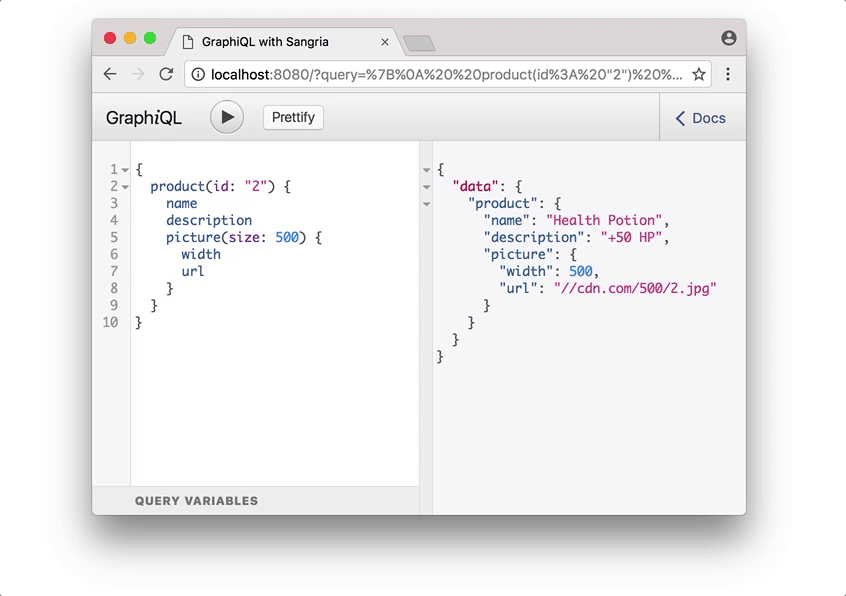
The result of this query execution would be following JSON:
{
"data": {
"product": {
"name": "Health Potion",
"description" :"+50 HP",
"picture": {
"width": 500,
"height": 500,
"url": "//cdn.com/500/2.jpg"
}
},
"products": [
{"name": "Cheesecake"},
{"name": "Health Potion"}
]
}
}
In this particular example I decided to use circe JSON library. In order to use it you will also need to add following library dependency in your SBT build:
"org.sangria-graphql" %% "sangria-circe" % "1.3.0"
Sangria supports most of the available JSON libraries, so you are not limited to a specific scala JSON implementation. In the next sections we will see an example of spray-json and play-json.
Now that we know how to define the schema and execute queries against it, let’s expose it as an HTTP endpoint.
Akka-http GraphQL Endpoint
First we need some basic akka-http setup. In this example we will use spray-json, so let’s add following library dependency:
"org.sangria-graphql" %% "sangria-spray-json" % "1.0.2"
Here is the basic akka-http server setup:
object Server extends App {
implicit val system = ActorSystem("sangria-server")
implicit val materializer = ActorMaterializer()
import system.dispatcher
val route: Route =
(post & path("graphql")) {
entity(as[JsValue]) { requestJson =>
graphQLEndpoint(requestJson)
}
} ~
get {
getFromResource("graphiql.html")
}
Http().bindAndHandle(route, "0.0.0.0", 8080)
}
Nothing special here. I also added a static endpoint that serves a single graphiql.html page which you can
find on GitHub (or use already
prepared graphiql.html from akka-http example).
It is a great tool that allows you edit and execute GraphQL queries directly in your browser.
Now that we have a basic setup, let’s define graphQLEndpoint method:
def graphQLEndpoint(requestJson: JsValue) = {
val JsObject(fields) = requestJson
val JsString(query) = fields("query")
val operation = fields.get("operationName") collect {
case JsString(op) => op
}
val vars = fields.get("variables") match {
case Some(obj: JsObject) => obj
case _ => JsObject.empty
}
QueryParser.parse(query) match {
// query parsed successfully, time to execute it!
case Success(queryAst) =>
complete(executeGraphQLQuery(queryAst, operation, vars))
// can't parse GraphQL query, return error
case Failure(error) =>
complete(BadRequest, JsObject("error" -> JsString(error.getMessage)))
}
}
According to GraphQL best practices we need to handle 3 fields in a request JSON body:
query-String- a GraphQL query as a stringvariables-Object- defines variables for your query (optional)operationName-String- a name of an operation, in case you defined several of them in the query (optional)
After we extracted these fields, we parse the query and execute it:
import sangria.marshalling.sprayJson._
def executeGraphQLQuery(query: Document, op: Option[String], vars: JsObject) =
Executor.execute(schema, query, new ProductRepo, variables = vars, operationName = op)
.map(OK -> _)
.recover {
case error: QueryAnalysisError => BadRequest -> error.resolveError
case error: ErrorWithResolver => InternalServerError -> error.resolveError
}
After you have defined all these methods, your akka-http based GraphQL server is ready to rock! Just start it and point your browser to http://localhost:8080. You will see GraphiQL console:
The GraphQL endpoint itself is exposed under http://localhost:8080/graphql.
You can find the full example on the GitHub: https://github.com/sangria-graphql/sangria-akka-http-example.
Play GraphQL Endpoint
The play implementation is very similar to akka-http. First we will use a different JSON implementation:
"org.sangria-graphql" %% "sangria-play-json" % "2.0.1"
Now you need to define a new route in your /conf/routes:
POST /graphql controllers.Application.graphql
In Application controller we need to define an action which is very similar to akka-http route and it will do following things:
- Extract
query,operationNameandvariablesfrom request JSON body - Parse the
query - Execute it against previously defined schema
class Application extends Controller {
def graphql = Action.async(parse.json) { request =>
val query = (request.body \ "query").as[String]
val operation = (request.body \ "operationName").asOpt[String]
val variables = (request.body \ "variables").toOption.flatMap {
case JsString(vars) => parseVariables(vars)
case obj: JsObject => obj
case _ => Json.obj()
}
def parseVariables(variables: String) =
if (variables.trim == "" || variables.trim == "null") Json.obj() else Json.parse(variables).as[JsObject]
QueryParser.parse(query) match {
// query parsed successfully, time to execute it!
case Success(queryAst) =>
executeGraphQLQuery(queryAst, operation, variables)
// can't parse GraphQL query, return error
case Failure(error: SyntaxError) =>
Future.successful(BadRequest(Json.obj("error" -> error.getMessage)))
}
}
}
We are using different response types here, but otherwise the query execution code is similar as well:
import sangria.marshalling.playJson._
def executeGraphQLQuery(query: Document, op: Option[String], vars: JsObject) =
Executor.execute(schema, query, new ProductRepo, operationName = op, variables = vars)
.map(Ok(_))
.recover {
case error: QueryAnalysisError => BadRequest(error.resolveError)
case error: ErrorWithResolver => InternalServerError(error.resolveError)
}
I recommend you to check out https://github.com/sangria-graphql/sangria-playground for more detailed example of a Play application.
Next steps
This page highlights only a small subset of sangria capabilities and features. I would recommend you to:
- Check out more advanced sangria tutorial available at “How To GraphQL”.
- Check in-depth sangria documentation.
- Play with sangria-playground mentioned above.
- Try out sangria-akka-http-example.
- Try out “Zero To GraphQL” example.